One thing that makes agriculture research difficult is the cornucopia of agricultural products. Globally, there are around 7,000 harvested species and innumerable subspecies, and even if 12 crops have come to dominate our food, it doesn’t stop 252 crops from being considered internationally important enough for the FAO to collect data on.
Source: Dimensions of Need: An atlas of food and agriculture, FAO, 1995
It takes 33 crop entries in the FAO database to account for 90% of global production, of which at 5 of those entries include multiple species.
Global production (MT), Source: FAO Statistics
Worse, different datasets collect information on different crops. Outside of the big three, there’s a Wild West of agriculture data to dissect. What’s a scientist to do?
The first step is to reduce the number of categories, to more than 2 (grains, other) and less than 252. By comparing the categories used by the FAO and the USDA, and also considering categories for major datasets I use, like the MIRCA2000 harvest areas and the Sacks crop calendar (and using a share of tag-sifting code to be a little objective), I came up with 10 categories:
- Cereals (wheat and rice)
- Coarse grains (not wheat and rice)
- Oilcrops
- Vegetables (including miscellaneous annuals)
- Fruits (including miscellaneous perennials– plants that “bear fruit”)
- Actives (spices, psychoactive plants)
- Pulses
- Tree nuts
- Materials (and decoratives)
- Feed
You can download the crop-by-crop (and other dataset category) mapping, currently as a PDF: A Crop Taxonomy
Still, most of these categories admit further division: fruits into melons, citrus, and non-citrus; splitting out the subcategory of caffeinated drinks from the actives category. What we need is a treemap for a cropmap! The best-looking maps I could make were using the R treemap package, shown below with rectangles sized by their global harvest area.
You can click through a more interactive version, using Google’s treemap library.
What does the world look like, with these categories? Here, it is colored by which category the majority production crop falls into:
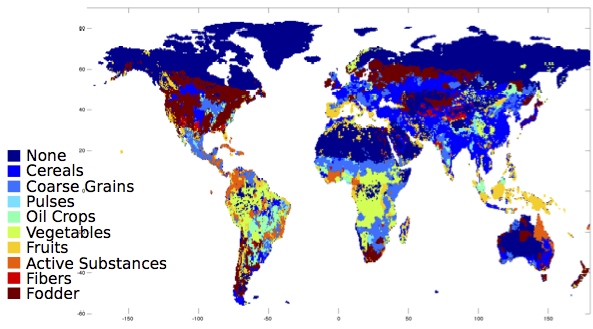
And since that looks rather cereal-dominated to my taste, here it is just considering fruits and vegetables:
For now, I will leave the interpretation of these fascinating maps to my readers.